建立和操作字串
Symfony 提供物件導向 API 來處理 Unicode 字串(以位元組、程式碼點和字形叢集為單位)。此 API 可透過 String 組件使用,您必須先在應用程式中安裝此組件
1
$ composer require symfony/string注意
如果您在 Symfony 應用程式之外安裝此組件,您必須在程式碼中引入 vendor/autoload.php 檔案,以啟用 Composer 提供的類別自動載入機制。請閱讀這篇文章以取得更多詳細資訊。
什麼是字串?
如果您已經知道在處理字串的上下文中,「程式碼點」或「字形叢集」是什麼,則可以跳過本節。否則,請閱讀本節以瞭解此組件使用的術語。
像英文這樣的語言只需要非常有限的字元和符號即可顯示任何內容。每個字串都是一系列字元(字母或符號),即使使用最有限的標準(例如 ASCII)也可以編碼。
然而,其他語言需要數千個符號才能顯示其內容。它們需要複雜的編碼標準,例如 Unicode,而「字元」之類的概念不再有意義。相反地,您必須處理這些術語
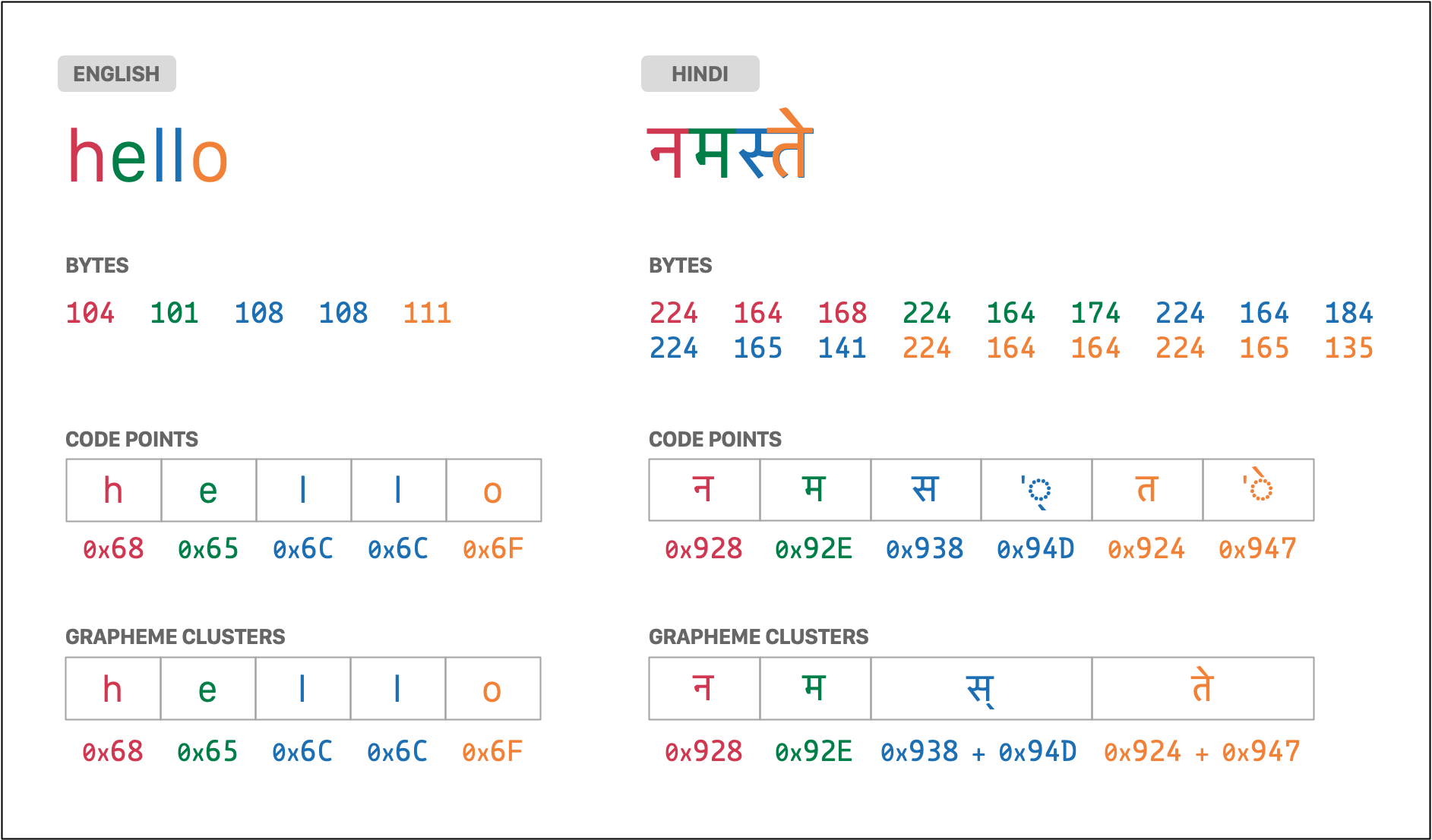
- 程式碼點:它們是資訊的原子單位。字串是一系列程式碼點。每個程式碼點都是一個數字,其含義由 Unicode 標準給定。例如,英文字母
A是U+0041程式碼點,日文假名の是U+306E程式碼點。 - 字形叢集:它們是一個或多個程式碼點的序列,顯示為單一圖形單位。例如,西班牙文字母
ñ是一個字形叢集,其中包含兩個程式碼點:U+006E=n(「拉丁小寫字母 N」) +U+0303=◌̃(「組合波浪號」)。 - 位元組:它們是為字串內容儲存的實際資訊。根據使用的標準(UTF-8、UTF-16 等),每個程式碼點可能需要一個或多個位元組的儲存空間。
下圖顯示了以英文 (hello) 和印地語 (नमस्ते) 寫成的同一個單字的位元組、程式碼點和字形叢集
用法
建立 ByteString、CodePointString 或 UnicodeString 類型的新物件,將字串內容作為其引數傳遞,然後使用物件導向 API 來處理這些字串
1 2 3 4 5 6 7 8 9 10 11 12
use Symfony\Component\String\UnicodeString;
$text = (new UnicodeString('This is a déjà-vu situation.'))
->trimEnd('.')
->replace('déjà-vu', 'jamais-vu')
->append('!');
// $text = 'This is a jamais-vu situation!'
$content = new UnicodeString('नमस्ते दुनिया');
if ($content->ignoreCase()->startsWith('नमस्ते')) {
// ...
}方法參考
建立字串物件的方法
首先,您可以使用以下類別建立準備好將字串儲存為位元組、程式碼點和字形叢集的物件
1 2 3 4 5 6 7 8
use Symfony\Component\String\ByteString;
use Symfony\Component\String\CodePointString;
use Symfony\Component\String\UnicodeString;
$foo = new ByteString('hello');
$bar = new CodePointString('hello');
// UnicodeString is the most commonly used class
$baz = new UnicodeString('hello');使用 wrap() 靜態方法來實例化多個字串物件
1 2 3 4 5 6 7
$contents = ByteString::wrap(['hello', 'world']); // $contents = ByteString[]
$contents = UnicodeString::wrap(['I', '❤️', 'Symfony']); // $contents = UnicodeString[]
// use the unwrap method to make the inverse conversion
$contents = UnicodeString::unwrap([
new UnicodeString('hello'), new UnicodeString('world'),
]); // $contents = ['hello', 'world']如果您使用大量的 String 物件,請考慮使用快捷功能來使您的程式碼更簡潔
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// the b() function creates byte strings
use function Symfony\Component\String\b;
// both lines are equivalent
$foo = new ByteString('hello');
$foo = b('hello');
// the u() function creates Unicode strings
use function Symfony\Component\String\u;
// both lines are equivalent
$foo = new UnicodeString('hello');
$foo = u('hello');
// the s() function creates a byte string or Unicode string
// depending on the given contents
use function Symfony\Component\String\s;
// creates a ByteString object
$foo = s("\xfe\xff");
// creates a UnicodeString object
$foo = s('अनुच्छेद');還有一些特殊的建構函式
1 2 3 4 5 6 7 8 9 10
// ByteString can create a random string of the given length
$foo = ByteString::fromRandom(12);
// by default, random strings use A-Za-z0-9 characters; you can restrict
// the characters to use with the second optional argument
$foo = ByteString::fromRandom(6, 'AEIOU0123456789');
$foo = ByteString::fromRandom(10, 'qwertyuiop');
// CodePointString and UnicodeString can create a string from code points
$foo = UnicodeString::fromCodePoints(0x928, 0x92E, 0x938, 0x94D, 0x924, 0x947);
// equivalent to: $foo = new UnicodeString('नमस्ते');轉換字串物件的方法
每個字串物件都可以轉換為其他兩種物件類型
1 2 3 4 5 6 7 8
$foo = ByteString::fromRandom(12)->toCodePointString();
$foo = (new CodePointString('hello'))->toUnicodeString();
$foo = UnicodeString::fromCodePoints(0x68, 0x65, 0x6C, 0x6C, 0x6F)->toByteString();
// the optional $toEncoding argument defines the encoding of the target string
$foo = (new CodePointString('hello'))->toByteString('Windows-1252');
// the optional $fromEncoding argument defines the encoding of the original string
$foo = (new ByteString('さよなら'))->toCodePointString('ISO-2022-JP');如果轉換因任何原因而無法進行,您將收到 InvalidArgumentException。
還有一個方法可以取得在某些位置儲存的位元組
1 2 3 4 5 6 7
// ('नमस्ते' bytes = [224, 164, 168, 224, 164, 174, 224, 164, 184,
// 224, 165, 141, 224, 164, 164, 224, 165, 135])
b('नमस्ते')->bytesAt(0); // [224]
u('नमस्ते')->bytesAt(0); // [224, 164, 168]
b('नमस्ते')->bytesAt(1); // [164]
u('नमस्ते')->bytesAt(1); // [224, 164, 174]與長度和空白字元相關的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// returns the number of graphemes, code points or bytes of the given string
$word = 'नमस्ते';
(new ByteString($word))->length(); // 18 (bytes)
(new CodePointString($word))->length(); // 6 (code points)
(new UnicodeString($word))->length(); // 4 (graphemes)
// some symbols require double the width of others to represent them when using
// a monospaced font (e.g. in a console). This method returns the total width
// needed to represent the entire word
$word = 'नमस्ते';
(new ByteString($word))->width(); // 18
(new CodePointString($word))->width(); // 4
(new UnicodeString($word))->width(); // 4
// if the text contains multiple lines, it returns the max width of all lines
$text = "<<<END
This is a
multiline text
END";
u($text)->width(); // 14
// only returns TRUE if the string is exactly an empty string (not even whitespace)
u('hello world')->isEmpty(); // false
u(' ')->isEmpty(); // false
u('')->isEmpty(); // true
// removes all whitespace (' \n\r\t\x0C') from the start and end of the string and
// replaces two or more consecutive whitespace characters with a single space (' ') character
u(" \n\n hello \t \n\r world \n \n")->collapseWhitespace(); // 'hello world'變更大小寫的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
// changes all graphemes/code points to lower case
u('FOO Bar Brİan')->lower(); // 'foo bar bri̇an'
// changes all graphemes/code points to lower case according to locale-specific case mappings
u('FOO Bar Brİan')->localeLower('en'); // 'foo bar bri̇an'
u('FOO Bar Brİan')->localeLower('lt'); // 'foo bar bri̇̇an'
// when dealing with different languages, uppercase/lowercase is not enough
// there are three cases (lower, upper, title), some characters have no case,
// case is context-sensitive and locale-sensitive, etc.
// this method returns a string that you can use in case-insensitive comparisons
u('FOO Bar')->folded(); // 'foo bar'
u('Die O\'Brian Straße')->folded(); // "die o'brian strasse"
// changes all graphemes/code points to upper case
u('foo BAR bάz')->upper(); // 'FOO BAR BΆZ'
// changes all graphemes/code points to upper case according to locale-specific case mappings
u('foo BAR bάz')->localeUpper('en'); // 'FOO BAR BΆZ'
u('foo BAR bάz')->localeUpper('el'); // 'FOO BAR BAZ'
// changes all graphemes/code points to "title case"
u('foo ijssel')->title(); // 'Foo ijssel'
u('foo ijssel')->title(allWords: true); // 'Foo Ijssel'
// changes all graphemes/code points to "title case" according to locale-specific case mappings
u('foo ijssel')->localeTitle('en'); // 'Foo ijssel'
u('foo ijssel')->localeTitle('nl'); // 'Foo IJssel'
// changes all graphemes/code points to camelCase
u('Foo: Bar-baz.')->camel(); // 'fooBarBaz'
// changes all graphemes/code points to snake_case
u('Foo: Bar-baz.')->snake(); // 'foo_bar_baz'
// changes all graphemes/code points to kebab-case
u('Foo: Bar-baz.')->kebab(); // 'foo-bar-baz'
// other cases can be achieved by chaining methods. E.g. PascalCase:
u('Foo: Bar-baz.')->camel()->title(); // 'FooBarBaz'7.1
localeLower()、localeUpper() 和 localeTitle() 方法在 Symfony 7.1 中引入。
7.2
kebab() 方法在 Symfony 7.2 中引入。
所有字串類別的方法預設都區分大小寫。您可以使用 ignoreCase() 方法執行不區分大小寫的操作
1 2
u('abc')->indexOf('B'); // null
u('abc')->ignoreCase()->indexOf('B'); // 1附加和前置方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
// adds the given content (one or more strings) at the beginning/end of the string
u('world')->prepend('hello'); // 'helloworld'
u('world')->prepend('hello', ' '); // 'hello world'
u('hello')->append('world'); // 'helloworld'
u('hello')->append(' ', 'world'); // 'hello world'
// adds the given content at the beginning of the string (or removes it) to
// make sure that the content starts exactly with that content
u('Name')->ensureStart('get'); // 'getName'
u('getName')->ensureStart('get'); // 'getName'
u('getgetName')->ensureStart('get'); // 'getName'
// this method is similar, but works on the end of the content instead of on the beginning
u('User')->ensureEnd('Controller'); // 'UserController'
u('UserController')->ensureEnd('Controller'); // 'UserController'
u('UserControllerController')->ensureEnd('Controller'); // 'UserController'
// returns the contents found before/after the first occurrence of the given string
u('hello world')->before('world'); // 'hello '
u('hello world')->before('o'); // 'hell'
u('hello world')->before('o', includeNeedle: true); // 'hello'
u('hello world')->after('hello'); // ' world'
u('hello world')->after('o'); // ' world'
u('hello world')->after('o', includeNeedle: true); // 'o world'
// returns the contents found before/after the last occurrence of the given string
u('hello world')->beforeLast('o'); // 'hello w'
u('hello world')->beforeLast('o', includeNeedle: true); // 'hello wo'
u('hello world')->afterLast('o'); // 'rld'
u('hello world')->afterLast('o', includeNeedle: true); // 'orld'填充和修剪方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
// makes a string as long as the first argument by adding the given
// string at the beginning, end or both sides of the string
u(' Lorem Ipsum ')->padBoth(20, '-'); // '--- Lorem Ipsum ----'
u(' Lorem Ipsum')->padStart(20, '-'); // '-------- Lorem Ipsum'
u('Lorem Ipsum ')->padEnd(20, '-'); // 'Lorem Ipsum --------'
// repeats the given string the number of times passed as argument
u('_.')->repeat(10); // '_._._._._._._._._._.'
// removes the given characters (default: whitespace characters) from the beginning and end of a string
u(' Lorem Ipsum ')->trim(); // 'Lorem Ipsum'
u('Lorem Ipsum ')->trim('m'); // 'Lorem Ipsum '
u('Lorem Ipsum')->trim('m'); // 'Lorem Ipsu'
u(' Lorem Ipsum ')->trimStart(); // 'Lorem Ipsum '
u(' Lorem Ipsum ')->trimEnd(); // ' Lorem Ipsum'
// removes the given content from the start/end of the string
u('file-image-0001.png')->trimPrefix('file-'); // 'image-0001.png'
u('file-image-0001.png')->trimPrefix('image-'); // 'file-image-0001.png'
u('file-image-0001.png')->trimPrefix('file-image-'); // '0001.png'
u('template.html.twig')->trimSuffix('.html'); // 'template.html.twig'
u('template.html.twig')->trimSuffix('.twig'); // 'template.html'
u('template.html.twig')->trimSuffix('.html.twig'); // 'template'
// when passing an array of prefix/suffix, only the first one found is trimmed
u('file-image-0001.png')->trimPrefix(['file-', 'image-']); // 'image-0001.png'
u('template.html.twig')->trimSuffix(['.twig', '.html']); // 'template.html'搜尋和取代方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
// checks if the string starts/ends with the given string
u('https://symfony.dev.org.tw')->startsWith('https'); // true
u('report-1234.pdf')->endsWith('.pdf'); // true
// checks if the string contents are exactly the same as the given contents
u('foo')->equalsTo('foo'); // true
// checks if the string content match the given regular expression.
u('avatar-73647.png')->match('/avatar-(\d+)\.png/');
// result = ['avatar-73647.png', '73647', null]
// You can pass flags for preg_match() as second argument. If PREG_PATTERN_ORDER
// or PREG_SET_ORDER are passed, preg_match_all() will be used.
u('206-555-0100 and 800-555-1212')->match('/\d{3}-\d{3}-\d{4}/', \PREG_PATTERN_ORDER);
// result = [['206-555-0100', '800-555-1212']]
// checks if the string contains any of the other given strings
u('aeiou')->containsAny('a'); // true
u('aeiou')->containsAny(['ab', 'efg']); // false
u('aeiou')->containsAny(['eio', 'foo', 'z']); // true
// finds the position of the first occurrence of the given string
// (the second argument is the position where the search starts and negative
// values have the same meaning as in PHP functions)
u('abcdeabcde')->indexOf('c'); // 2
u('abcdeabcde')->indexOf('c', 2); // 2
u('abcdeabcde')->indexOf('c', -4); // 7
u('abcdeabcde')->indexOf('eab'); // 4
u('abcdeabcde')->indexOf('k'); // null
// finds the position of the last occurrence of the given string
// (the second argument is the position where the search starts and negative
// values have the same meaning as in PHP functions)
u('abcdeabcde')->indexOfLast('c'); // 7
u('abcdeabcde')->indexOfLast('c', 2); // 7
u('abcdeabcde')->indexOfLast('c', -4); // 2
u('abcdeabcde')->indexOfLast('eab'); // 4
u('abcdeabcde')->indexOfLast('k'); // null
// replaces all occurrences of the given string
u('https://symfony.dev.org.tw')->replace('http://', 'https://'); // 'https://symfony.dev.org.tw'
// replaces all occurrences of the given regular expression
u('(+1) 206-555-0100')->replaceMatches('/[^A-Za-z0-9]++/', ''); // '12065550100'
// you can pass a callable as the second argument to perform advanced replacements
u('123')->replaceMatches('/\d/', function (string $match): string {
return '['.$match[0].']';
}); // result = '[1][2][3]'合併、分割、截斷和反轉方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
// uses the string as the "glue" to merge all the given strings
u(', ')->join(['foo', 'bar']); // 'foo, bar'
// breaks the string into pieces using the given delimiter
u('template_name.html.twig')->split('.'); // ['template_name', 'html', 'twig']
// you can set the maximum number of pieces as the second argument
u('template_name.html.twig')->split('.', 2); // ['template_name', 'html.twig']
// returns a substring which starts at the first argument and has the length of the
// second optional argument (negative values have the same meaning as in PHP functions)
u('Symfony is great')->slice(0, 7); // 'Symfony'
u('Symfony is great')->slice(0, -6); // 'Symfony is'
u('Symfony is great')->slice(11); // 'great'
u('Symfony is great')->slice(-5); // 'great'
// reduces the string to the length given as argument (if it's longer)
u('Lorem Ipsum')->truncate(3); // 'Lor'
u('Lorem Ipsum')->truncate(80); // 'Lorem Ipsum'
// the second argument is the character(s) added when a string is cut
// (the total length includes the length of this character(s))
// (note that '…' is a single character that includes three dots; it's not '...')
u('Lorem Ipsum')->truncate(8, '…'); // 'Lorem I…'
// the third optional argument defines how to cut words when the length is exceeded
// the default value is TruncateMode::Char which cuts the string at the exact given length
u('Lorem ipsum dolor sit amet')->truncate(8, cut: TruncateMode::Char); // 'Lorem ip'
// returns up to the last complete word that fits in the given length without surpassing it
u('Lorem ipsum dolor sit amet')->truncate(8, cut: TruncateMode::WordBefore); // 'Lorem'
// returns up to the last complete word that fits in the given length, surpassing it if needed
u('Lorem ipsum dolor sit amet')->truncate(8, cut: TruncateMode::WordAfter); // 'Lorem ipsum'7.2
truncate 函數的 TruncateMode 參數在 Symfony 7.2 中引入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// breaks the string into lines of the given length
u('Lorem Ipsum')->wordwrap(4); // 'Lorem\nIpsum'
// by default it breaks by white space; pass TRUE to break unconditionally
u('Lorem Ipsum')->wordwrap(4, "\n", cut: true); // 'Lore\nm\nIpsu\nm'
// replaces a portion of the string with the given contents:
// the second argument is the position where the replacement starts;
// the third argument is the number of graphemes/code points removed from the string
u('0123456789')->splice('xxx'); // 'xxx'
u('0123456789')->splice('xxx', 0, 2); // 'xxx23456789'
u('0123456789')->splice('xxx', 0, 6); // 'xxx6789'
u('0123456789')->splice('xxx', 6); // '012345xxx'
// breaks the string into pieces of the length given as argument
u('0123456789')->chunk(3); // ['012', '345', '678', '9']
// reverses the order of the string contents
u('foo bar')->reverse(); // 'rab oof'
u('さよなら')->reverse(); // 'らなよさ'ByteString 新增的方法
這些方法僅適用於 ByteString 物件
1 2 3
// returns TRUE if the string contents are valid UTF-8 contents
b('Lorem Ipsum')->isUtf8(); // true
b("\xc3\x28")->isUtf8(); // falseCodePointString 和 UnicodeString 新增的方法
這些方法僅適用於 CodePointString 和 UnicodeString 物件
1 2 3 4 5 6 7 8 9 10 11
// transliterates any string into the latin alphabet defined by the ASCII encoding
// (don't use this method to build a slugger because this component already provides
// a slugger, as explained later in this article)
u('नमस्ते')->ascii(); // 'namaste'
u('さよなら')->ascii(); // 'sayonara'
u('спасибо')->ascii(); // 'spasibo'
// returns an array with the code point or points stored at the given position
// (code points of 'नमस्ते' graphemes = [2344, 2350, 2360, 2340]
u('नमस्ते')->codePointsAt(0); // [2344]
u('नमस्ते')->codePointsAt(2); // [2360]Unicode 等價是 Unicode 標準的規範,即不同的程式碼點序列代表相同的字元。例如,瑞典文字母 å 可以是單一程式碼點 (U+00E5 = 「帶圈的拉丁小寫字母 A」) 或兩個程式碼點的序列 (U+0061 = 「拉丁小寫字母 A」 + U+030A = 「組合圈」)。normalize() 方法允許選擇正規化模式
1 2 3 4 5 6
// these encode the letter as a single code point: U+00E5
u('å')->normalize(UnicodeString::NFC);
u('å')->normalize(UnicodeString::NFKC);
// these encode the letter as two code points: U+0061 + U+030A
u('å')->normalize(UnicodeString::NFD);
u('å')->normalize(UnicodeString::NFKD);延遲載入字串
有時,使用前面章節中介紹的方法建立字串並不是最佳的。例如,考慮一個雜湊值,它需要一定的計算才能獲得,而您最終可能不會使用它。
在這些情況下,最好使用 LazyString 類別,它允許儲存一個字串,其值僅在您需要時才產生
1 2 3 4 5 6 7 8 9
use Symfony\Component\String\LazyString;
$lazyString = LazyString::fromCallable(function (): string {
// Compute the string value...
$value = ...;
// Then return the final value
return $value;
});回呼函數僅在程式執行期間請求延遲字串的值時才會執行。您也可以從 Stringable 物件建立延遲字串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class Hash implements \Stringable
{
public function __toString(): string
{
return $this->computeHash();
}
private function computeHash(): string
{
// Compute hash value with potentially heavy processing
$hash = ...;
return $hash;
}
}
// Then create a lazy string from this hash, which will trigger
// hash computation only if it's needed
$lazyHash = LazyString::fromStringable(new Hash());使用表情符號
這些內容已移至Emoji 組件文件。
Slugger
在某些情況下,例如 URL 和檔案/目錄名稱,使用任何 Unicode 字元都不安全。slugger 將給定的字串轉換為另一個僅包含安全 ASCII 字元的字串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~');
// $slug = 'Workspace-settings'
// you can also pass an array with additional character substitutions
$slugger = new AsciiSlugger('en', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// if there is no symbols map for your locale (e.g. 'en_GB') then the parent locale's symbols map
// will be used instead (i.e. 'en')
$slugger = new AsciiSlugger('en_GB', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// for more dynamic substitutions, pass a PHP closure instead of an array
$slugger = new AsciiSlugger('en', function (string $string, string $locale): string {
return str_replace('❤️', 'love', $string);
});單字之間的分隔符號預設為破折號 (-),但您可以將另一個分隔符號定義為第二個引數
1 2
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~', '/');
// $slug = 'Workspace/settings'slugger 在應用其他轉換之前,會將原始字串音譯為拉丁文字。原始字串的語言環境會自動偵測,但您可以明確定義它
1 2 3 4 5 6
// this tells the slugger to transliterate from Korean ('ko') language
$slugger = new AsciiSlugger('ko');
// you can override the locale as the third optional parameter of slug()
// e.g. this slugger transliterates from Persian ('fa') language
$slug = $slugger->slug('...', '-', 'fa');在 Symfony 應用程式中,您不需要自行建立 slugger。感謝服務自動裝配,您可以透過使用 SluggerInterface 類型提示服務建構函式引數來注入 slugger。注入的 slugger 的語言環境與請求語言環境相同
1 2 3 4 5 6 7 8 9 10 11 12 13 14
use Symfony\Component\String\Slugger\SluggerInterface;
class MyService
{
public function __construct(
private SluggerInterface $slugger,
) {
}
public function someMethod(): void
{
$slug = $this->slugger->slug('...');
}
}Slug 表情符號
您也可以將表情符號轉譯器與 slugger 結合使用,以將任何表情符號轉換為其文字表示形式
1 2 3 4 5 6 7 8 9 10
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slugger = $slugger->withEmoji();
$slug = $slugger->slug('a 😺, 🐈⬛, and a 🦁 go to 🏞️', '-', 'en');
// $slug = 'a-grinning-cat-black-cat-and-a-lion-go-to-national-park';
$slug = $slugger->slug('un 😺, 🐈⬛, et un 🦁 vont au 🏞️', '-', 'fr');
// $slug = 'un-chat-qui-sourit-chat-noir-et-un-tete-de-lion-vont-au-parc-national';如果您想為表情符號使用特定的語言環境,或使用來自 GitHub、Gitlab 或 Slack 的簡碼,請使用 withEmoji() 方法的第一個引數
1 2 3 4 5 6 7
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slugger = $slugger->withEmoji('github'); // or "en", or "fr", etc.
$slug = $slugger->slug('a 😺, 🐈⬛, and a 🦁');
// $slug = 'a-smiley-cat-black-cat-and-a-lion';Inflector
在某些情況下,例如程式碼產生和程式碼內省,您需要將單字從單數/複數轉換為單數/複數。例如,若要瞭解與 adder 方法相關聯的屬性,您必須從複數 (addStories() 方法) 轉換為單數 ($story 屬性)。
大多數人類語言都有簡單的複數化規則,但同時它們也定義了許多例外情況。例如,英文中的一般規則是在單字末尾加上 s (book -> books),但即使對於常見單字也有許多例外情況 (woman -> women、life -> lives、news -> news、radius -> radii 等)
此組件提供 EnglishInflector 類別,可自信地將英文單字從單數/複數轉換為單數/複數
1 2 3 4 5 6 7 8 9 10 11
use Symfony\Component\String\Inflector\EnglishInflector;
$inflector = new EnglishInflector();
$result = $inflector->singularize('teeth'); // ['tooth']
$result = $inflector->singularize('radii'); // ['radius']
$result = $inflector->singularize('leaves'); // ['leaf', 'leave', 'leaff']
$result = $inflector->pluralize('bacterium'); // ['bacteria']
$result = $inflector->pluralize('news'); // ['news']
$result = $inflector->pluralize('person'); // ['persons', 'people']這兩種方法傳回的值始終是陣列,因為有時無法為給定的單字判斷唯一的單數/複數形式。
Symfony 也為其他語言提供 inflector
1 2 3 4 5 6 7 8 9 10 11
use Symfony\Component\String\Inflector\FrenchInflector;
$inflector = new FrenchInflector();
$result = $inflector->singularize('souris'); // ['souris']
$result = $inflector->pluralize('hôpital'); // ['hôpitaux']
use Symfony\Component\String\Inflector\SpanishInflector;
$inflector = new SpanishInflector();
$result = $inflector->singularize('aviones'); // ['avión']
$result = $inflector->pluralize('miércoles'); // ['miércoles']7.2
SpanishInflector 類別在 Symfony 7.2 中引入。
注意
如果您需要實作自己的 inflector,Symfony 提供了 InflectorInterface。